

Hey there, future data engineers! I’m Adarsh Yadav, a data engineer who’s navigated the tough world of tech interviews and learned what it takes to succeed. Welcome to Day 1 of my 60-day SQL challenge, designed to help you master SQL for data engineer interviews and land your dream job at top companies like Meta, Google, Amazon, Netflix, and more. SQL is the heart of data engineering, accounting for 40–50% of interview questions. Over the next 60 days, I’ll share one real SQL interview question daily, sourced from candidate experiences on platforms like Glassdoor and LeetCode, or drawn from my own work as a data engineer.
This challenge will cover everything you need to excel in data engineer interviews, from basic joins and aggregations to advanced topics like subqueries, window functions, and query optimization. Each post will include a problem, a detailed solution, a schema/dataset for practice, and tips to boost your SQL skills. You can practice in any database—online tools like SQL Fiddle or offline ones like SQL Server PostgreSQL or MySQL. I’ll explain solutions clearly in the comments and answer your questions to keep you motivated. If you stick with this challenge, I guarantee you’ll be ready to crush any SQL interview. Let’s dive into our first question from Meta!
Why SQL Matters for Data Engineer Interviews
Data engineers are the backbone of data pipelines, transforming raw data into insights that drive business decisions. SQL is your go-to tool for querying large datasets, building reports, and designing data models. In data engineer interviews, companies test your ability to write efficient, accurate queries and solve real-world problems. For example, Meta might ask you to analyze social network data, Google could focus on user behavior metrics, and Amazon often tests e-commerce analytics. SQL questions make up 40–50% of the technical interview, so mastering it is critical.
This challenge is built to prepare you for those high-pressure moments. Each question will teach you how to think like a data engineer—logically, methodically, and practically. I’ll share practical tips from my experience, like how to structure queries for clarity or optimize for performance. By the end, you’ll not only write flawless SQL but also explain your solutions confidently, a key skill for data engineer interviews. Let’s get started with today’s Meta problem!
Problem: Calculate Famous Percentage for Meta Users
Company: Meta
Level: Hard
Concepts Covered: Aggregate Functions, Joins, Subqueries, Distinct Counts
You’re given a table called famous with two columns:
user_id: The ID of a user on the platformfollower_id: The ID of a follower (also a user on the platform)
This table represents follower relationships, where each follower_id follows the corresponding user_id. For example, a row (1, 2) means user 2 follows user 1.
Goal: Calculate the Famous Percentage for each user, defined as:
Famous Percentage = (Number of followers a user has) / (Total number of users on the platform)
Return the user_id and their famous_percentage (as a percentage, e.g., 20.00%) for every user with at least one follower. Sort the results by user_id for clarity.
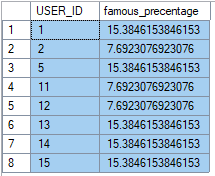
Expected Output:
A table with user_id and famous_percentage columns, showing each user’s follower percentage relative to the total number of unique users.
Schema and Data Setup for Practice for Data Engineer
You can practice this question in any database, such as SQL Server, PostgreSQL, MySQL, or another tool you prefer. If you’re new to databases or need help setting one up, comment below with your setup (e.g., “I’m on Windows and want to use MSSQL”), and I’ll share a step-by-step tutorial tailored to you.
Here’s the schema and sample data to get you started:
CREATE TABLE famous (user_id INT, follower_id INT);
INSERT INTO famous VALUES
(1, 2), (1, 3), (2, 4), (5, 1), (5, 3),
(11, 7), (12, 8), (13, 5), (13, 10),
(14, 12), (14, 3), (15, 14), (15, 13);This creates a table with 13 rows, representing follower relationships:
- User 1 has followers 2 and 3 (2 followers).
- User 5 has followers 1 and 3 (2 followers).
- User 15 has followers 14 and 13 (2 followers).
Copy this schema into your database and run the query to test your solution. The data is small but mimics real-world social graph scenarios.
Before jumping to Solution Try on your own. Once successfully got the output please comment the query
How to Solve This SQL Question for Data Engineer Interviews This Meta data engineer interview question is rated “hard” because it combines multiple SQL concepts to calculate a percentage across a relational dataset. It’s a perfect test of your ability to handle social network data, a common challenge at Meta. Here’s the approach, broken down into clear steps:
Please try on your own before jumping to solution
Approach:
- Get all distinct users using a UNION on
user_idandfollower_id - Count followers per
user_id(usingGROUP BY user_id) - Join the follower counts to the total user count.
- Calculate the famous percentage.
Solution:
This approach requires careful handling of duplicates and aggregations, making it an excellent prep question for data engineer interviews.
Step-by-Step Solution and Explanation Here’s the SQL query to solve the Famous Percentage problem, using Common Table Expressions (CTEs) for clarity and maintainability
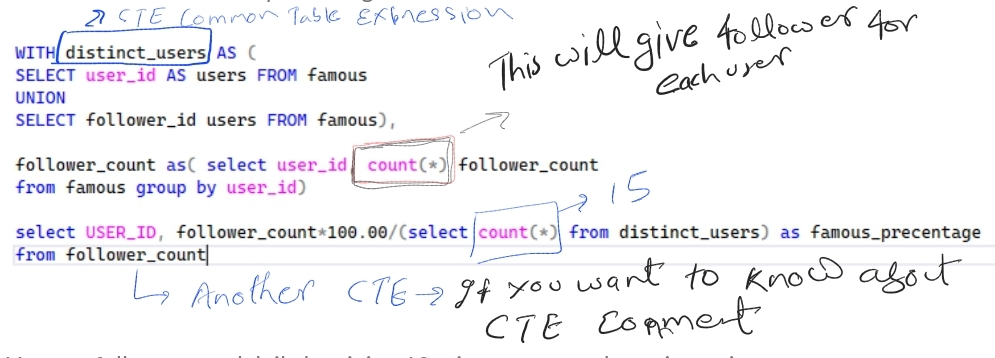
WITH distinct_users AS (
SELECT user_id AS users FROM famous
UNION
SELECT follower_id users FROM famous),
follower_count as( select user_id, count(*) follower_count
from famous group by user_id)
select USER_ID, follower_count*100.00/(select count(*) from distinct_users) as famous_precentage
from follower_countExplanation:
- Takes each user_id and follower_count from the follower_count CTE.
- Divides follower_count by the total number of users (via a subquery: SELECT COUNT(*) FROM distinct_users).
- Multiplies by 100.00 to convert to a percentage (100.00 ensures floating-point division).
- Uses ROUND(…, 2) to format the result to two decimal places (e.g., 20.00%).
- Orders by user_id for readability.
Output Example: If there are 10 unique users, and user 1 has 2 followers, their famous_percentage is (2 / 10) * 100 = 20.00%. The result lists each user_id
In an interview, Meta might ask follow-ups, like including users with zero followers or handling NULL values. Explaining your query and its trade-offs (e.g., “I used CTEs for clarity, but a join could reduce subqueries”) shows you’re thinking like a data engineer. This challenge will prepare you for both the coding and communication parts of the interview with at least one follower and their percentage.
You can follow me and daily by giving 10 min we can crack any interview.
Day 2: coming soo#n

What is with you are using
Alright, gotta say, ggbbbet has been pretty decent to me. The site’s easy to navigate, and I haven’t had any major issues cashing out. Plus, their bonuses are actually worth grabbing sometimes. Check it out at ggbbbet.
Betzarcasino is alright. Got a pretty decent selection of slots and live dealer games. Payouts have been reliable so far, which is always a big plus in my book. Maybe you’ll have some luck at betzarcasino.
Bet666login has a very clean interface, which is cool. Not a ton of bells and whistles just easy to place your bets, you know? Check them out! bet666login.